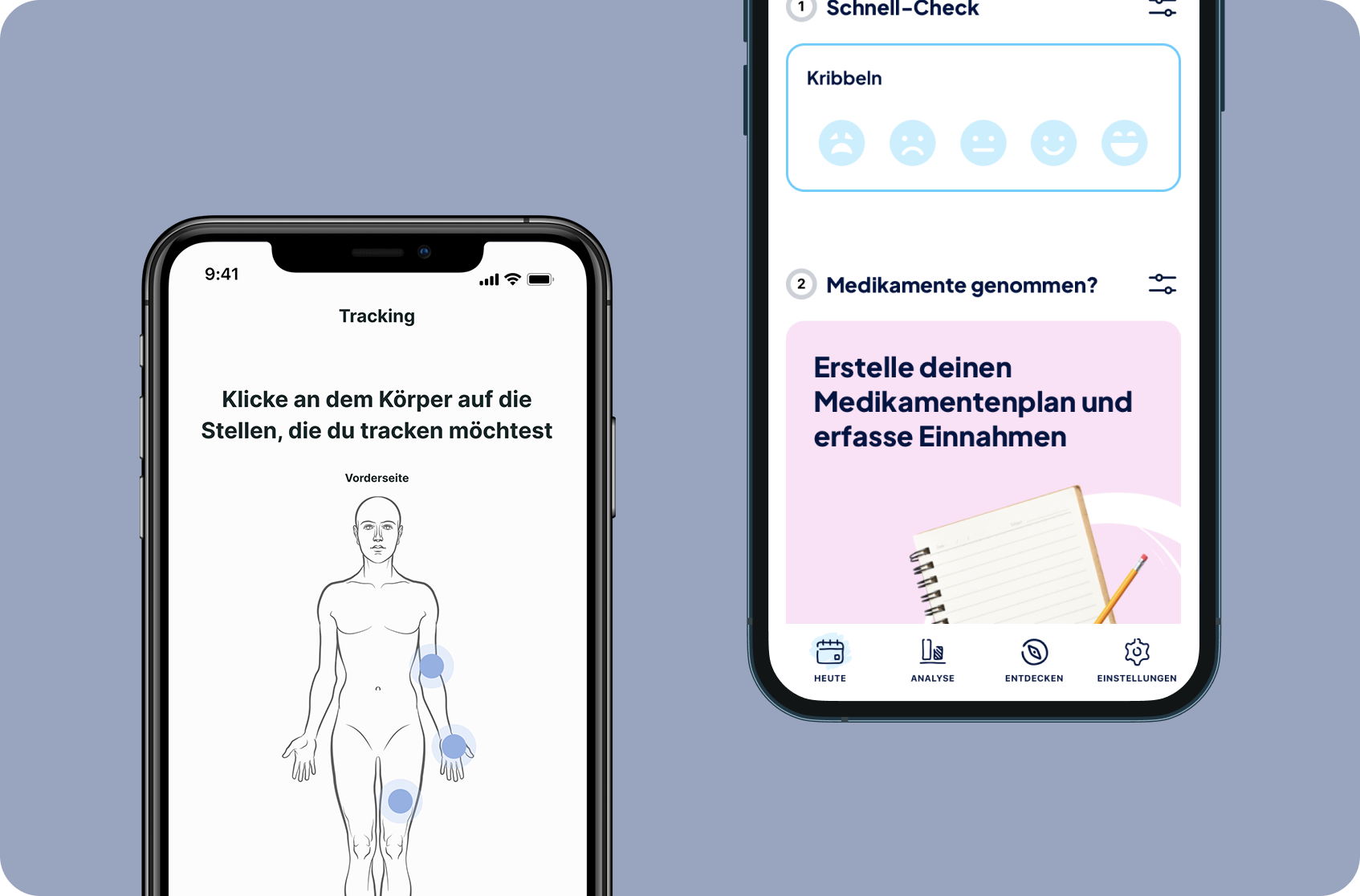
PERMEA MONITOR
ADD ON DIGITAL COMPANION
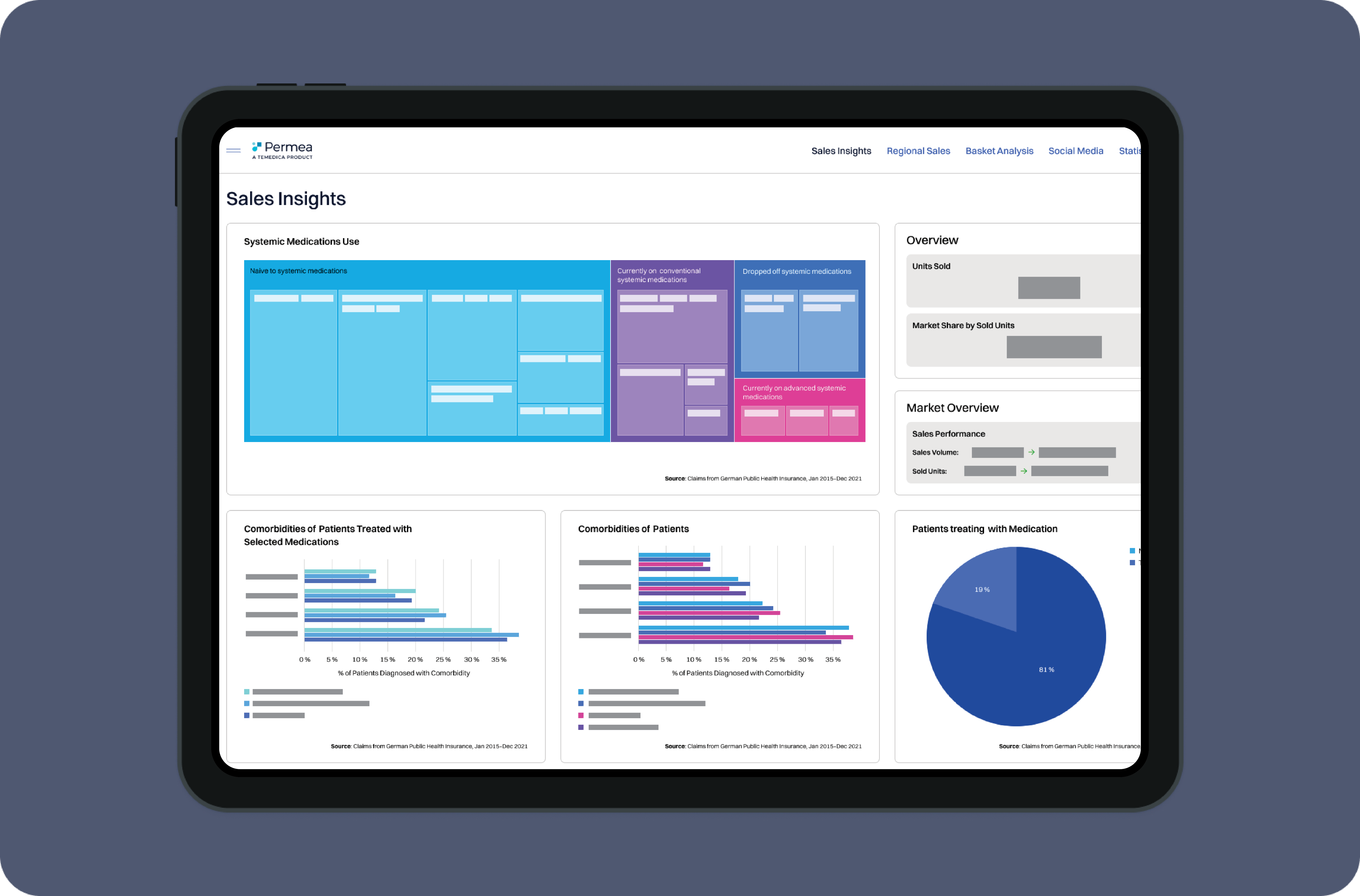
Permea delivers real-world insights in a highly intuitive dashboard that can be customised to address specific requirements of the pharmaceutical enterprise.
Unlock the potential of direct patient access and leverage Patient-Reported Outcomes (PROs) as a dynamic data source that informs on patient behaviors and outcomes. Enhance patient activation through treatment information, empowering patients to proactively inquire about your treatment options.